Optimizing parallel performance of under and over resampling with Tensorflow
- When training with imbalanced (very large) data set with multi class multi labeled images
- Learning Visual Features from Large Weakly Supervised Data
- Armand Joulin, Laurens van der Maaten, Allan Jabri, Nicolas Vasilache
- https://arxiv.org/abs/1511.02251
- Exploring the Limits of Weakly Supervised Pretraining
- Dhruv Mahajan, Ross Girshick, Vignesh Ramanathan, Kaiming He, Manohar Paluri, Yixuan Li, Ashwin Bharambe, Laurens van der Maaten
- https://arxiv.org/abs/1805.00932
- Learning Visual Features from Large Weakly Supervised Data
- Not enough with rejection sampling
- in case, some samples are too rare, so it normally does not exist in one batch or even in many rounds of batches.
- rejection is a job of consuming too much of resources.
- With Tensorflow dataset API
- over-and-under sampling with tensorflow from stackoverflow
- Tensorflow data input pipeline performance Guide
- Optimizing performance : https://www.tensorflow.org/guide/performance/datasets#optimizing_performance
- Parallelize Data Transformation : https://www.tensorflow.org/guide/performance/datasets#parallelize_data_transformation
- tested with Tensorflow 1.13. Tesla P40 8 GPUs, with Intel 48 CPUs and 251 GB physical memory.
- In principle, the only bottleneck of data pipeline ought be GPUs. Let me assume that GPU time cannot be reduced.
Offline Preparation Flow
- Collect sample distribution A
- crawled and/or tagged data with not too much considering of the balance between class labels
- Design resampled(target) distribution B
- considered for the class balance of labels
- Make a transformation (vector) T from A to B
- Each column is (re)sampling probability from samples in A to make samples in B
- If colume value p in T is less than 1, some of samples 100 * (1 - p) % are goint to be dropped.
- p is a survival probability. i.e. (1-p) is a drop probability.
- If columen value p is more than 1, samples are replicated p times.
- p is a replication ratio.
- Let’s call p as a ratio factor
Online Training Flow
- Loading tfrecords
- shuffle data records in memory (large shuffle)
- parsing record labels
- giving uniform probability(bet) for each record
- under resampling with map and flat_map
- drop some of records whose probability(bet) is lower than each label’s threshold(=ratio factor) given T
- over resampling with map and flat_map
- replicate some of records N times whose ratio factor p(=N.xxx) given T is more than a integer 1 (N > 1)
- shuffle data samples in memory (small shuffle)
- parsing record images
- decode jpegs into Tensors
- make batch from parsed records
- prefetch before and after (parsing)map-and-batch.
- train with batches
Disk I/O, Memory, CPUs, Bus I/O, and GPUs parallelism
- Because of under sampling, resampling wastes much of disk I/O.
- Lots of samples are dropped right after they are loaded from disks.
- So with undersampling, disk I/O is much heavier burden compared to the ordinary sampling.
- And because of low latency of disk I/O, it takes too long to wait to load next data records after computation.
- dropping-out can be continued indefinitely
- So prefetch is necessary between file reading and record parsing.
- The records in data files might be unshuffled.
- So shuffle data right after they are loaded into memory
- Record parsing is CPU’s job.
- Having multi CPUs, map with parallel_calls is useful for concurrent parsing.
- Undersampling before oversampling
- undersampling dumps away some of records.
- it reduces the size of list of data sequences.
- it is waste of CPU resources to work with the data (in short time after) going to be dropped out.
- tf.dataset.filter is not useful, because it doesn’t provide parallelism.
- map with parallel_calls is useful, but map handles the internal contents of records, not the record set itself.
- to handle duplication or elimination of records, flat_map is necessary.
- like this
dataset = dataset.map(undersample_filter_fn, num_parallel_calls=num_parallel_calls) dataset = dataset.flat_map(lambda x : x)flat_map with the identity lambda function is just for merging survived (and empty) records
#parallel calls of map('A'), map('B'), and map('C') map('A') = 'AAAAA' # replication of A 5 times map('B') = '' # B is dropped map('C') = 'CC' # replication of C twice # merging all map results flat_map('AAAA,,CC') = 'AAAACC'https://www.tensorflow.org/images/datasets_parallel_map.png
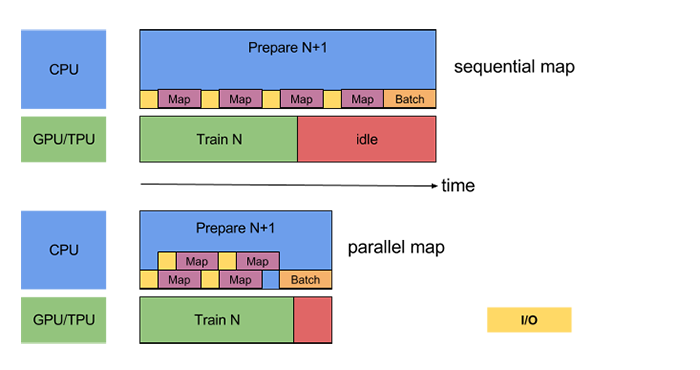
- decoding compressed images like jpeg is a totally CPU bound job
- and can be parallelized in map with parallel calls and should be.
- (Shuffle) buffer(list) of decoded image tensors occupy very large bulk of memory.
- Transmitting of image tensors causes huge bus I/O, because of memory copying.
- So after decode image files like JPEG, any operation which needs mem-copy should be minimized.
- Not to make GPUs hang out, disk I/O, bus I/O, CPU resource should not be exausted at all times.
# Summary
- All ops in order
- file load with parallel interleave
- prefetch
- large shuffle
- parallel map for parse_record(label)
- parallel map for undersample
- flat_map
- prefetch
- parallel map for oversample
- flat_map
- small shuffle
- prefetch
- parallel map for parse_record(image)
- prefetch
- batch